
Conserving Token Usage and Reducing AI Inference Costs in Production
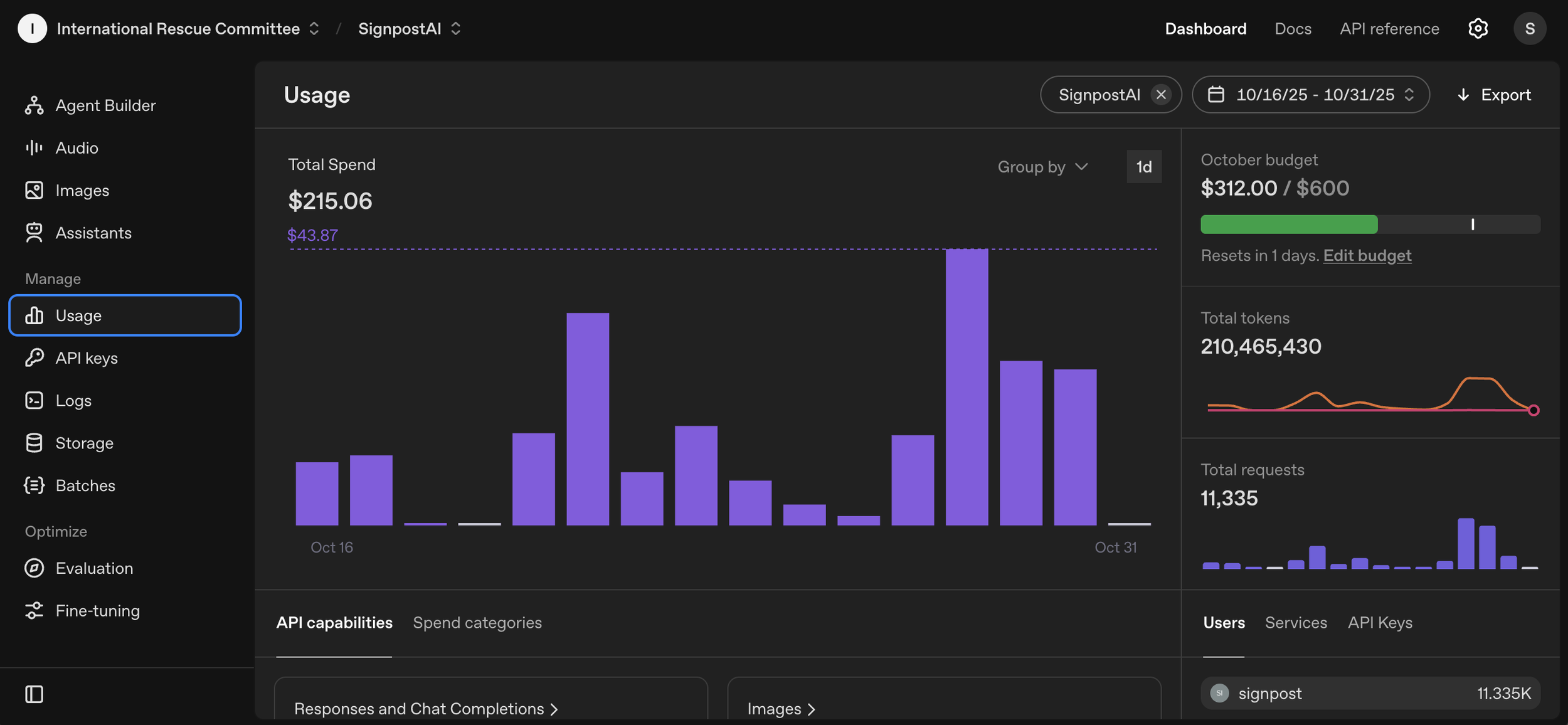
An image of SignpostAI daily spend rate in OpenAI platform. An increase in token use in late October comes from the launch of a context and heavy-token agent.
How smart architecture beats raw model power when scaling AI chatbots - Brian Greenberg, Senior Program Manager October 2025
At Signpost AI, we run multiple large-scale chat deployments across different contexts—from refugee information services to economic development coaching. After serving millions of conversations across 10 countries, we've learned one critical lesson: the single biggest factor that determines whether a system scales affordably is how well it handles context.
Good design beats raw model power almost every time.
Pick a Model That's Fit-for-Purpose
The first decision that drives cost is model choice. But here's the counterintuitive truth: bigger or "smarter" models aren't always better.
In our experience, most of the performance variance in chat-based systems doesn't come from the model's reasoning ability—it comes from how effectively context has been engineered for the use case.
Long-context models are often necessary because production systems have large system prompts, retrieval-augmented context, and other background information that must be kept in scope. Models like GPT-4o mini, GPT-4o nano, or Gemini 2.0 Flash tend to hit a good balance of context length, speed, and cost. (Model offerings are constantly changing, so stay up-to-date with emerging trends.)
What matters most is not how "smart" the model is, but how efficiently it can handle long input windows at scale.
The Hidden Reality of Production Costs
In production, input context usually dominates cost. Even if a chatbot's responses are short, the hidden system prompt, the retrieved documents, and the conversation history can all add up fast.
Smaller and cheaper models often perform just as well when the surrounding context and scaffolding are well engineered. Reasoning models are rarely a good choice for user-facing interactions unless they're doing something rare and expensive, like a one-off content generation task.
For everything else, it's usually better to split workflows across tiers: fast lightweight models for simple steps, and heavier reasoning models only when absolutely required.
Context Kills (Your Budget)
Context bloat is the silent cost driver in every production chatbot we've tested. Input token usage has been at least 10x the size of output token usage in every production chatbot we've developed.
The conversation may look short, but under the hood there's a lot going on: system prompts, retrieved snippets, and conversation memory all pile up.
How to Keep Context Under Control
The way to keep this under control is to prune aggressively.
Retrieval systems should be tuned to return only what's needed, when it's needed. If retrieval can happen without calling the LLM, even better. The more that happens outside the model, the less you pay for compute.
Long-context models are powerful tools, but they don't give you a license to dump everything into the prompt. Treat the context window like a shared budget and spend it wisely.
System prompts deserve the same discipline. It's easy to overload them with instructions, translations, or repeated content. Keep prompts modular and inject details dynamically instead of loading everything up front.
Conversation history is another area that needs attention. Long chats can get expensive quickly. Compression, summarization, or hard limits on history length can all help. The system should "remember" what it needs to, not every word that's ever been said.
Monitoring What Happens in the Wild
Even with good design, it's not always obvious how context lengths will behave once people start using the system. Real usage brings variables that are hard to predict ahead of time—things like average engagement length, message style, and how much retrieval actually fires.
That's why monitoring matters.
Token usage should be tracked by component: system prompt size, retrieval payload, conversation history, and output. Dashboards or logs that show the average and high-end token counts per request are useful for spotting drift over time.
If you see sudden jumps in input size, it usually means something upstream has changed—maybe a retrieval bug or a prompt that started growing silently. Regular reviews of real conversation traces are also worth doing. They help catch inefficiencies that only show up under real user behavior.
Simple Rules That Go a Long Way
Through our work scaling AI systems across diverse humanitarian contexts, we've developed some core principles:
Modularize prompts and only include what's relevant per turn
Set token budgets and measure against them
Limit retrieved chunks to the top few most relevant
Limit the size of retrieved chunks
Cache static content whenever possible
Track input vs. output tokens so you can see where the cost is coming from
Use the cheapest capable model for each task
Monitor, monitor, monitor
Balancing Performance and Cost
Reducing inference cost isn't just a financial optimization, it's a sustainability problem.
We want AI systems that can scale to serve thousands or millions of people without breaking budgets or creating unnecessary environmental harm. That requires discipline in design and an understanding of how models actually use context.
At Signpost AI, we've learned that model choice matters far less than architecture. A small model with clean scaffolding and selective retrieval often performs better, faster, and cheaper than a larger one that's fed too much noise.
The goal is simple: make the model see only what it needs, when it needs it, and nothing more.
Signpost AI enables responsible AI use for humanitarian programs at scale. Learn more about our approach to building efficient, ethical AI systems at signpost.ai.