
Stress-Testing AI at the Humanitarian Frontier: Findings from Signpost Colombia's First AI Simulation Round
At Signpost AI — an initiative of the Signpost Project, led by the IRC — our mission is to deploy responsible, agentic AI systems that extend the reach of humanitarian information services to people in crisis. Across 20 countries and 25 languages, Signpost programs already serve 19 million users. The Colombia program, InfoPa'lante, supports Venezuelan migrants navigating services, rights, and documentation in an environment defined by urgency, vulnerability, and frequently incomplete information.
On March 12, 2026, we completed Round 1 of a structured simulation study of the InfoPa'lante Colombia AI chatbot — 112 conversations, 3 rounds each, delivered via Telerivet and the AI App. This post presents a technical account of what we built, what we tested, what failed, and what it costs.
Architecture and Simulation Design
The InfoPa'lante agent is a retrieval-augmented generation (RAG) system grounded in an injected knowledge base managed via Directus, surfacing service-directory data to an underlying LLM. Conversations are routed through Telerivet for SMS-channel delivery and a web-based AI App interface. Human escalation is handled via Zendesk (or equivalent CRM), with moderators triaging flagged conversations.
The simulation was deliberately risk-weighted. Rather than sampling uniformly from expected interaction types, scenarios were generated from three source pools:
Harm taxonomy-derived cases — systematically covering categories from the Signpost risk framework, including domestic violence, trafficking, acute mental health crises, and documentation emergencies.
Historical conversation data — real interaction patterns from prior moderator-handled conversations.
Low-literacy user interaction models — stress-testing the agent's ability to handle poorly structured, ambiguous, or incomplete inputs.
Scenarios also included out-of-scope cases — questions the agent was explicitly not designed to answer — to evaluate graceful degradation and redirection behavior.
For this round, escalation protocols were adapted from the InfoDigna Mexico risk framework, as the Colombia-specific Risk Framework remained under review at the time of simulation.
Key Performance Metrics
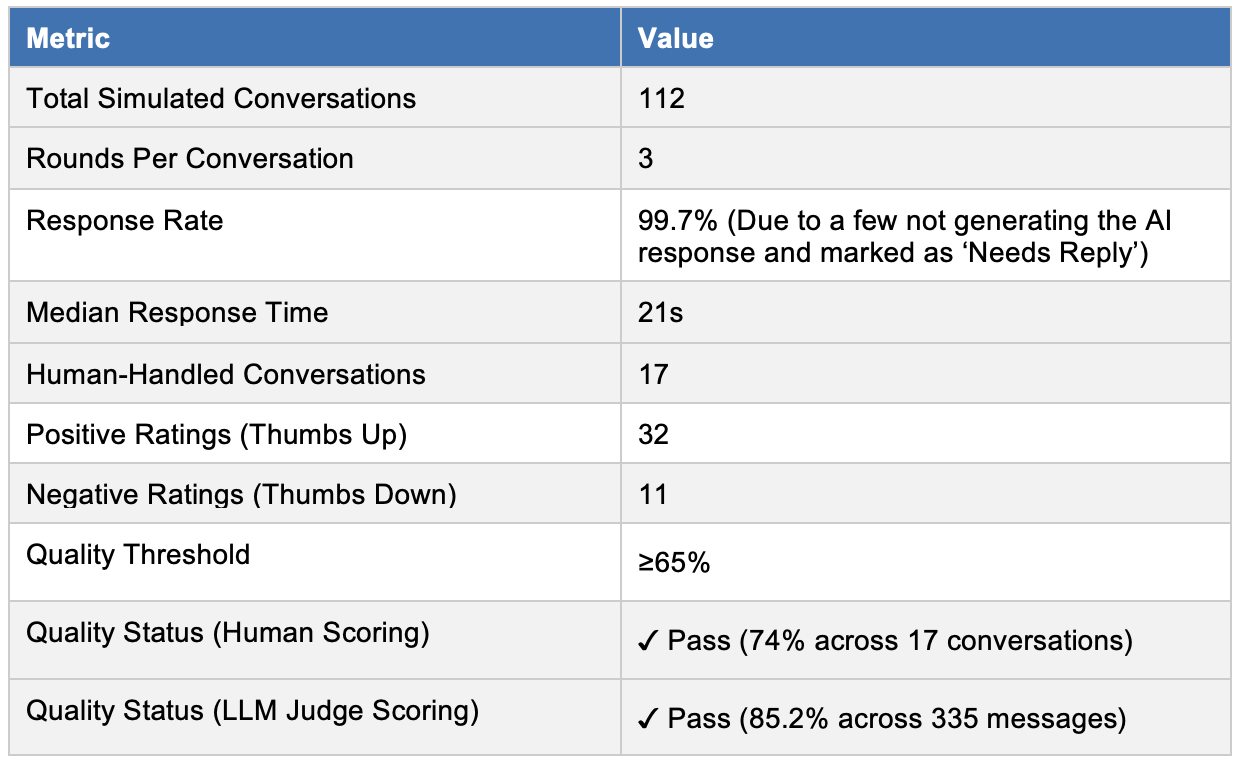
Both the human-scored and LLM-as-Judge tracks cleared the 65% quality threshold. Of 335 evaluated messages, 11 (3.3%) scored below 65 — a low absolute failure rate, but the failure patterns are operationally significant and discussed in detail below.
Risk Category Distribution
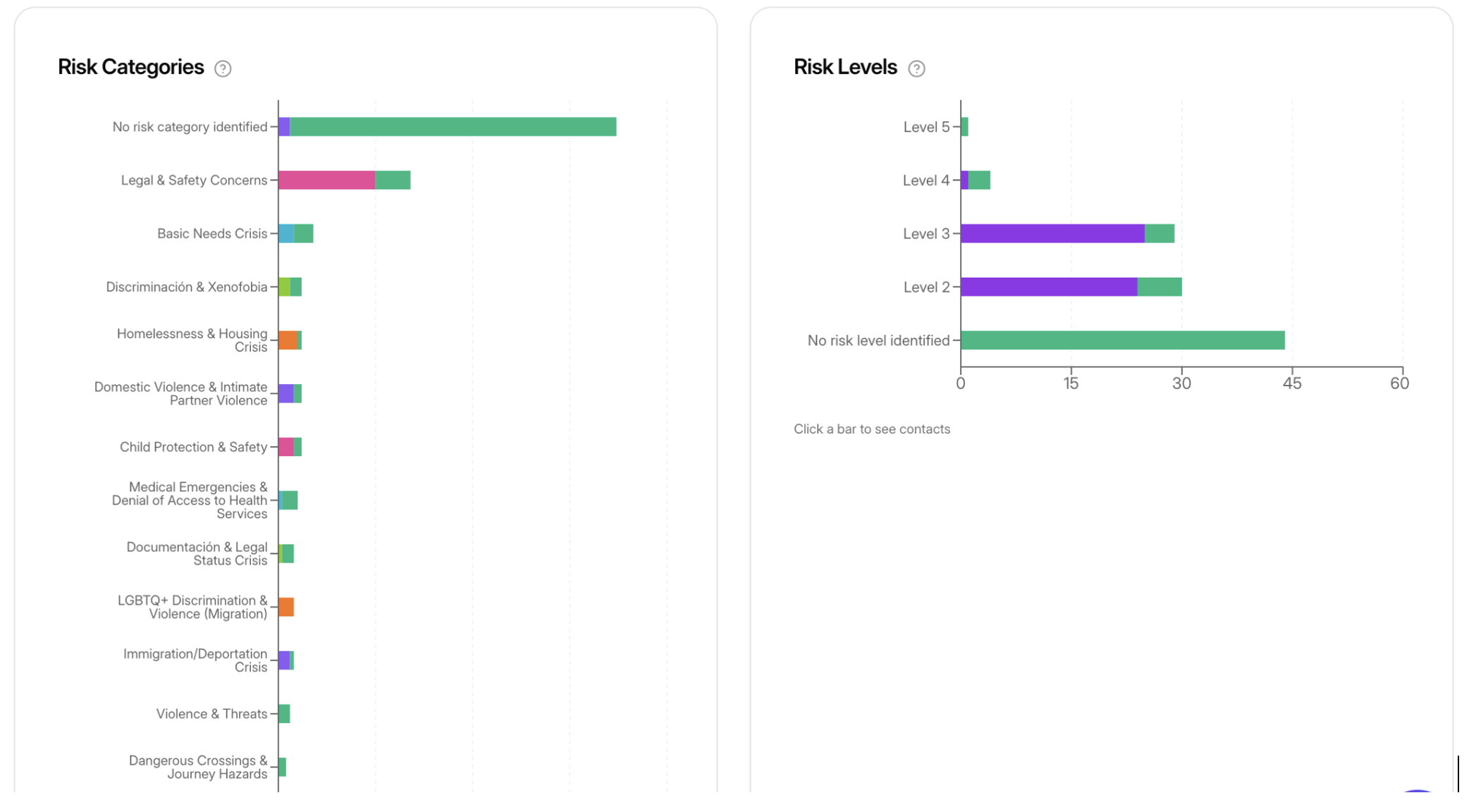
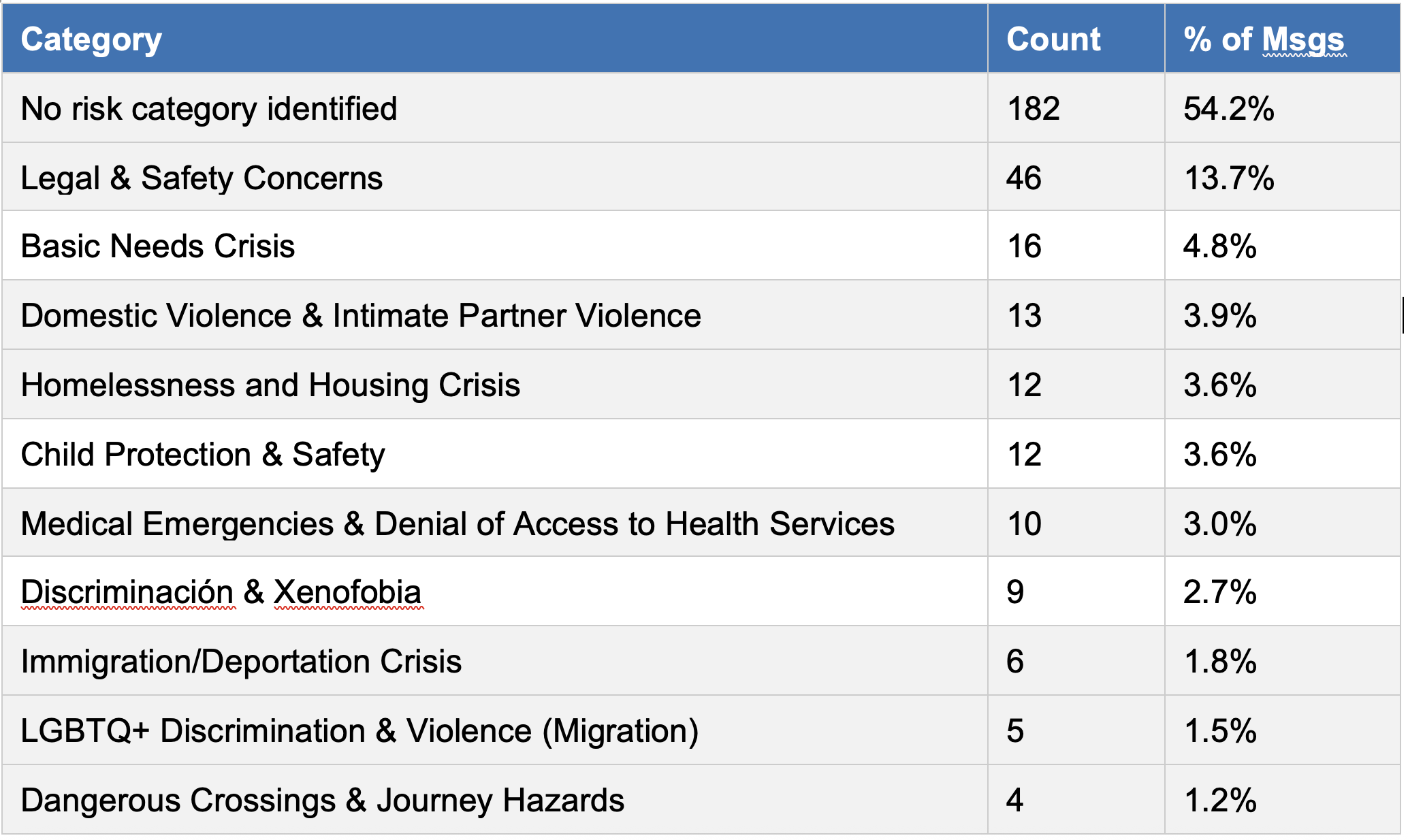
The simulation was structured to surface high-risk scenarios. Of 336 categorized messages, 45.8% carried at least one risk flag. The breakdown:
Excerpt from risk simulation
A notable observation: Immigration/Deportation Crisis (1.8%), Dangerous Crossings (1.2%), and Documentation & Legal Status Crisis (2.4%) appear disproportionately low given what is known from prior moderator-handled data. This almost certainly reflects a simulation coverage gap rather than genuine low prevalence — the scenarios used in this round underrepresented border and displacement contexts. These categories are scheduled for priority expansion in Round 2.
LLM-as-Judge: Failure Mode Analysis
We used an LLM-as-Judge evaluation pipeline to score all 335 messages on a 0–100 scale against a defined quality rubric. Eleven responses fell below the 65-point threshold. The failure modes cluster into four distinct patterns:
Pattern 1 — Irrelevant service retrieval (hallucination / stale index) Two responses returned completely wrong services — an abortion clinic and a laundry service in response to a vaccination query; a list of unrelated programs in response to a grocery/food assistance question. Root cause: the knowledge base has not been recently audited, and the underlying LLM intermittently hallucinates plausible-sounding but fabricated links when the RAG index returns no confident match.
Pattern 2 — Redundant clarification requests (entity extraction failure) Four responses asked the user to supply information they had already provided — most commonly, city of residence — despite that information appearing clearly in the prior turn. This points to a context-window or entity-tracking failure in the prompt architecture, not a knowledge-base issue.
Pattern 3 — Out-of-scope deflection without redirection Two responses involving travel to Ecuador resulted in the agent redirecting users to the InfoPa'lante Ecuador channel without answering the stated question. While scope boundaries are intentional, the failure to provide any substantive information before deflecting — particularly when the user re-asked — scored poorly on both helpfulness and harm-avoidance rubrics.
Pattern 4 — Insufficient specificity on legal/immigration questions Three responses involving pension rights for Venezuelans, PPT/PEP documentation status checks, and legal entry with a passport-only returned vague or incomplete answers. In one case the agent omitted the critical distinction between the Tarjeta de Movilidad Fronteriza's permitted movement scope and the formal visa requirement for longer stays — a legally meaningful error.
Human Escalation Analysis
Of 112 simulated conversations, 17 were routed to human moderators (15.2% escalation rate). Across those 17 conversations, the human moderator quality score averaged 74%, passing the ≥65% threshold.
A critical operational finding emerged from reviewing internal comments on corrected responses:
Stale service data was flagged in 5 of 11 corrected responses — the dominant failure mode. The Directus-managed service directory contains contact details and availability data for organizations including Fundación ProBono that have not been verified recently. This is an operational dependency, not a model deficiency.
One escalation failure was identified where the agent proceeded to list service options for a complex documentation case involving young children, rather than routing to a human. This suggests the escalation classifier is under-triggering on cases involving child protection where the user's framing is not explicitly distress-coded.
Two responses contained legally imprecise border crossing information for the Norte de Santander / Cúcuta corridor, requiring correction.
The moderator quality assessment (average 7.5–8/10) was broadly positive: the agent demonstrates accessible, empathetic language and good progressive specificity — asking clarifying questions to narrow its support as conversations develop. The main corrective feedback: introduce more colloquial register to better match how Venezuelan migrants naturally communicate, and extend geographic coverage beyond Bogotá-centric service data.
Response Time: Quantified Impact
Historical moderator response-time data for the Colombia program during working hours (Monday–Friday, full history):
Response Time Bracket Share of Conversations > 24 hours 15% 8–24 hours 9% 1–8 hours 2% 0–1 hour 28% No reply 45%
The no-reply rate of 45% is the operationally critical figure. Nearly half of all inbound conversations received zero response under the moderator-only model. The AI agent's median response time of 21 seconds — against a historical moderator median of 28 minutes — represents a 98.75% reduction in first-response latency. For users reaching out in crisis, that latency gap is not a performance metric; it is the difference between receiving information and receiving nothing.
Cost-Efficiency Analysis
Baseline: Traditional Moderator Model (FY23)
The FY23 moderator-based model served 22,707 annual interactions using 2 moderators, with a cost per engagement of $2.00 (inclusive of virtual two-way engagement, platform management, content production, reporting, and moderator time allocated at 72% to virtual engagement). Total annual cost: $45,414.
AI-Powered Model
At an average of 3 exchange rounds per conversation, the AI model costs approximately $0.015 per client — derived from API token costs for a 3-round incoming/outgoing exchange. Applied to the 112 simulated conversations: $1.68 total, against $224 for the equivalent moderator-only load — a 99.25% cost reduction per interaction.
Projected to FY23 annual volume (22,707 interactions): $340.60/year versus $45,414.
Hybrid Model
A fully automated model is not operationally appropriate for this context. Human oversight must remain structurally embedded, particularly for high-risk escalations. The simulation's risk-weighted design produced an escalation rate of 46.43% — higher than would be expected in production (by design, since the simulation was stress-tested for risk scenarios). Under a hybrid cost model:
Blended cost = (53.57% × $0.015) + (46.43% × $2.00) = $0.94 per client (projected)
Model Cost/Client Annual Cost (22,707) Annual Saving
Moderator-Based $2.00 $45,414
AI-Powered $0.015 $340.60 $45,073 (99.25%)
Hybrid (AI + Human) $0.94 $21,344 $24,069 (53%)
The hybrid model alone frees $24,069 annually — resources that could be reinvested in content maintenance, additional language support, or expanded geographic coverage.
It should be noted that with the introduction of LLM-as-Judge evaluation, moderator allocation to virtual engagement is expected to decrease from the current 72%, further improving the effective cost per interaction in the hybrid model.
Pre-Launch Requirements
The simulation identified a clear set of requirements that must be completed before production deployment:
1. Full knowledge base audit. The Directus service directory must be comprehensively reviewed: all service details verified, all links tested, all whitelisted website content confirmed as current. Stale data is the single highest-risk failure mode — it causes the agent to actively mislead vulnerable users at critical decision points.
2. Hallucination mitigation for out-of-index queries. When the RAG index returns no confident match, the LLM should be constrained to acknowledge the gap and redirect rather than generating plausible-sounding but fabricated resources. This requires prompt-level guardrails and potentially confidence-threshold gating on knowledge-base retrieval.
3. Entity extraction in multi-turn context. The prompt architecture needs adjustment to reliably carry forward entities (city, nationality, document type) from prior turns, eliminating redundant clarification requests that degrade user experience and inflate conversation length.
4. Colombia Risk Framework finalization. The agent is currently operating on adapted InfoDigna Mexico escalation protocols. The Colombia-specific framework needs to be finalized and integrated before launch to ensure escalation logic reflects local legal context and service landscape.
5. Expanded simulation coverage. Round 2 should explicitly include border crossing and displacement scenarios, migration-corridor-specific queries (Cúcuta / Norte de Santander in particular), and a broader geographic distribution of service questions beyond Bogotá. Immigration/deportation crisis, dangerous crossings, and legal status emergencies are currently underrepresented relative to their expected real-world prevalence.
Conclusion
Round 1 of the InfoPa'lante Colombia simulation validates the core architecture while surfacing a well-defined set of pre-launch deficiencies. The agent communicates accessibly, responds with contextual empathy, and progressively refines its support across conversation turns — strong foundations for a tool serving Venezuelan migrants in complex, high-stakes situations.
The cost and response-time data make a structurally compelling case for the hybrid model: a 98.75% reduction in first-response latency, a 53% reduction in cost per interaction, and — critically — the elimination of the 45% no-reply rate that characterizes the current moderator-only system.
What stands between the current simulation results and production deployment is not model capability — it is content governance. The knowledge base must be treated as a live operational dependency, not a one-time setup task. Stale service data, broken links, and hallucinated resources in a humanitarian context are not UX degradations; they are potential harms to people making urgent decisions with limited information and limited recourse.
With the content audit completed, the Colombian Risk Framework finalized, and Round 2 simulation coverage broadened, the InfoPa'lante agent is well-positioned to become a trusted, scalable information resource for Venezuelan migrants navigating Colombia's services and legal landscape.
For more on Signpost's AI research and responsible deployment methodology, visit signpostai.org and signpost.ngo.