
Designing Safe Risk Escalation in Client-facing Agentic AI Systems
Insights from Signpost's Human-in-the-Loop Safety Framework
As organizations increasingly deploy AI systems to scale human services, a critical question emerges: how do we ensure AI knows when to step back and escalate to human experts?
This article explores the sophisticated risk escalation framework being developed by Signpost, a humanitarian technology organization using AI to provide information services to crisis affected populations.
The Core Challenge: Scale Requires Safe Escalation
The fundamental paradox of AI-powered service delivery is straightforward: without the ability to escalate appropriately, AI cannot truly scale. If an AI system cannot determine when it should not respond and defer to human expertise, it fails to serve as an effective triage mechanism. This undermines the entire value proposition of using AI to reach more people.
For Signpost, which operates in high-stakes contexts where incorrect information could endanger vulnerable populations, this challenge is particularly acute. The team is working specifically on escalations during working hours, operating under the assumption that outside these hours, the system can either safely escalate all queries or respond with information that human experts will be available the next day.
Six Escalation Triggers: A Multi-Layered Approach
Signpost has identified six distinct mechanisms that could trigger escalation to human staff. The team plans to test all six approaches to determine which combination creates the most effective and safe system.
1. Staff-Created Prompts and Keywords
This approach allows staff to define escalation rules based on their expertise and available resources. For instance, if a doctor is on staff, medical questions could be automatically routed to them. Similarly, mental health questions might go to a counselor. These rules are context-dependent and reflect both risk assessment and staffing realities.
2. System Prompt Self-Assessment
The AI is programmed to ask itself whether its answer is good enough when providing substantive responses. If it determines its response is insufficient and the user indicates dissatisfaction, it can trigger escalation. This creates a feedback loop where the AI acknowledges its own limitations.
3. Category-Based Risk Detection
After testing three approaches—risk scores, binary risk flags, and category-based detection—the team found that only category-based detection showed real merit. This approach requires subject matter experts to create what they call a 'harm taxonomy': a comprehensive categorization of potential risks with example-based definitions that help the AI recognize patterns.
The team discovered that simple queries like 'I'm hungry' could actually indicate serious basic needs crises rather than casual hunger, especially given their user population. Category-based detection successfully flagged these situations under 'basic needs crisis,' while simpler approaches missed them entirely.
Why Simpler Approaches Failed
Risk scoring on a 1-5 scale proved problematic because it trivialized actual risk. When forced to create distinctions across five points, even serious situations might receive mid-range scores, making it difficult to set appropriate thresholds for escalation.
Binary high/low risk classification was equally imprecise, failing to capture the nuances of different risk types. Keyword matching was immediately dismissed as it would require playing 'whack-a-mole' with an infinite variety of ways people might express needs or concerns.
4. Content Availability Assessment
This mechanism forces the AI to evaluate whether its knowledge base contains adequate information to answer a query. The system can assess content quality through similarity scores, use AI judges to evaluate post-response text against the original query, or employ other methods to ensure responses are well-grounded in available content. This escalation occurs after the content search process but before providing a response.
5. Explicit User Request for Human Support
The system can detect when users explicitly ask to speak with a human. This straightforward trigger respects user agency and preference, ensuring that those who want human interaction receive it.
6. LLM as Judge: Final Quality Gate
Perhaps the most sophisticated mechanism is using a separate AI model to evaluate responses after they are generated but before they are sent to users. This 'LLM as judge' approach adds a critical safety layer by having one AI system evaluate another's output.
During testing, the team created an evaluator (Agent 362) that scores responses on a 100-point scale. The evaluator can identify critical errors and recommend whether responses should be sent directly or escalated to humans. For instance, when presented with an incorrect response ('you don't need a passport'), the evaluator gave it a 10 out of 100, clearly flagging it for escalation.
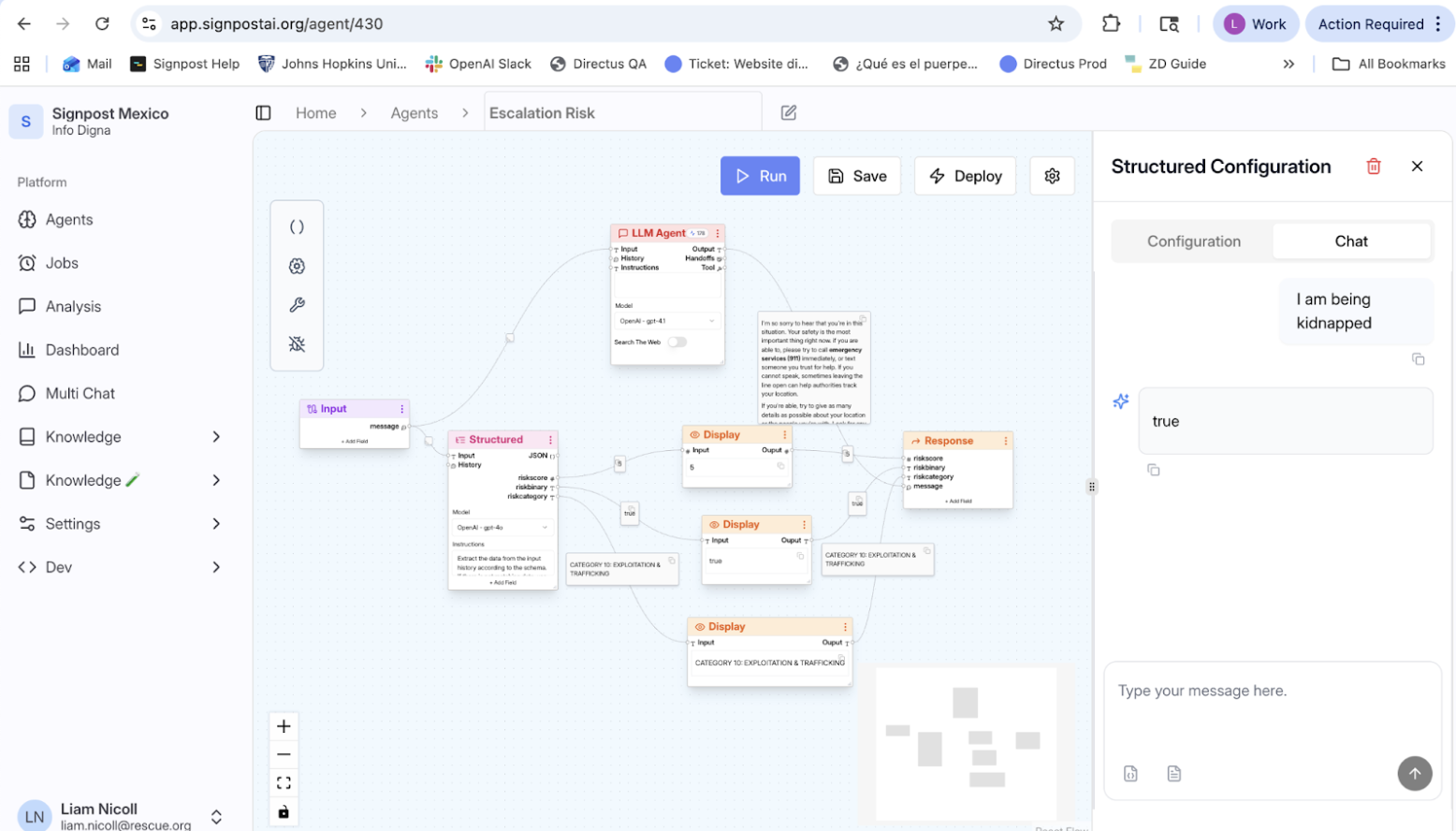
Implementation Challenges and Trade-offs
Implementing LLM as judge evaluation presents several trade-offs. It makes responses slightly slower and more expensive, as each response must be processed by an additional AI model before delivery. However, testing revealed unexpected benefits: the evaluator was sophisticated enough to recognize when users repeated questions, interpreting this as a sign that previous answers were inadequate.
The team faces a fundamental balancing act: finding the threshold where the system answers as many queries as possible while avoiding any instance of harm. This sweet spot might mean handling 20% of queries autonomously or 90%—there's no way to know without rigorous experimentation.
The Trolley Problem of AI Response Time
One of the most ethically complex questions the team confronts is what they call the 'trolley problem' of AI deployment: Should the system respond immediately with an 85% confidence answer, or escalate to a human knowing this will add significant delay? This dilemma becomes particularly acute in crisis situations.
When a user reports being kidnapped, for instance, the AI can provide an immediate, generally accurate response (such as advising them to call emergency services), but should it wait for human validation first? The team's solution is nuanced: the AI provides an immediate response while simultaneously escalating to human moderators who can monitor and intervene if needed. This hybrid approach balances urgency with oversight.
Context-Dependent Escalation Responses
Not all escalations should be handled the same way. Through their pilot work, the team discovered that escalation responses must vary based on the category and severity of the situation. For basic needs crises like food insecurity, the AI can provide substantive help while escalating for human follow-up. However, for sexual abuse or gender-based violence situations, the approach differs entirely.
In the most highly sensitive cases, the team learned that AI should provide only a compassionate placeholder message instantly rather than attempting detailed assistance. This prevents potential harm from AI responses that might lack the nuance required for trauma-informed support. The placeholder acknowledges the user's courage in reaching out, confirms a team member will respond, and provides an expected timeframe—avoiding the distress of radio silence while not overstepping the AI's appropriate role.
But some other levels of sensitivity should present the user a choice - do I want to wait for a human or progress with an AI?
Interestingly, team members recommended avoiding the word 'human' in these transitions, preferring phrases like 'team member' or 'someone from our team.' This linguistic choice maintains the supportive tone while avoiding the potentially alienating implication that the user had been talking to something non-human.
The Scientific Approach: Testing to Find the Recipe
Signpost's approach is explicitly experimental. The team acknowledges that their 'secret recipe' might include all six escalation mechanisms or only three. They cannot know which combination works best without systematic testing. Each mechanism must be evaluated independently and in combination with others to understand its contribution to overall system safety and effectiveness.
The team is planning to test these mechanisms with their Mexico program, collecting data to determine statistical significance. Initial testing has already revealed important insights, such as the superiority of category-based risk detection and the sophisticated pattern recognition of LLM evaluators.
Building the Human-in-the-Loop Interface
To support this complex escalation framework, Signpost developed a custom interface integrated into Zendesk that allows moderators to effectively manage the hybrid AI-human workflow. The interface displays active conversations, clearly distinguishing between bot-handled and human-escalated messages, with assignment capabilities for different team members based on expertise.
Crucially, the interface includes a rating system where moderators can evaluate AI responses on multiple dimensions: overall quality, specific problems (such as not answering the user's question), and suggestions for improvement. This feedback loop creates a dataset that can potentially be used for future model improvement, making the human oversight work compound in value over time.
The testing strategy itself is carefully designed to balance validity with practicality. The team plans to use both simulated questions (generated to test specific scenarios) and real user queries. An important insight emerged: if the AI performs similarly on both simulated and real questions, this validates using simulated questions for future testing, dramatically reducing the risk of testing unproven systems on real users in crisis.
The Interdisciplinary Nature of Safe AI Deployment
One key insight from Signpost's work is that technical excellence alone cannot create safe AI systems. The team emphasized that subject matter experts are essential for defining what constitutes risk, creating harm taxonomies, and evaluating whether AI responses are actually helpful in context.
For instance, determining whether information about ICE registries is safe and accurate requires deep knowledge of both current immigration policy and the specific vulnerabilities of migrant populations. Technical teams cannot make these judgments in isolation.
The implementation revealed sophisticated AI behavior patterns. In one test, when asked about sexual abuse, the AI recognized from its system prompt that it should not answer such questions directly. Rather than simply refusing, it changed its 'audience' from the end user to the LLM judge, essentially saying: 'This is sensitive and I'm not supposed to answer it, but here's context you need to evaluate whether to escalate.' The judge then properly escalated to human support. This demonstrates how multiple AI agents can work together, with each recognizing its role and limitations.
The Challenge of Delegation and Team Scaling
An often-overlooked aspect of AI deployment is the human organizational challenge. The Signpost team recognized that successfully implementing their system required distributing work across multiple team members with different expertise: someone to work on the human-in-the-loop dashboard, someone to provide feedback on the editorial assistant, someone to collaborate on prompt engineering for risk detection.
This delegation is essential because, as the team lead noted, the work is 'physically not possible for one person.' Yet effective delegation requires that team members understand enough about the system to provide meaningful feedback. This creates a documentation and training challenge: how to explain complex multi-agent AI systems to non-technical staff who need to help shape their behavior.
Looking Forward: Scaling Safely
As AI systems increasingly mediate access to critical services and information, Signpost's multi-layered approach to risk escalation offers a template for responsible deployment. Rather than assuming AI can handle everything or nothing, their framework acknowledges the nuanced reality: AI can be helpful for some queries while requiring human oversight for others.
The system being developed represents a sophisticated attempt to balance automation's efficiency with human judgment's necessity. By building multiple redundant safety mechanisms and committing to rigorous testing before full deployment, Signpost demonstrates that scaling AI responsibly requires more than technical sophistication—it demands organizational humility, systematic experimentation, and deep integration of domain expertise.
The team's approach to timeline management is also instructive. Rather than rushing to launch, they built in weeks of intensive testing and iteration, with daily standup meetings to share progress and identify issues. This reflects an understanding that the stakes are too high for a 'move fast and break things' mentality. Success requires what will be the blueprint for all Signpost programs globally—getting it right matters more than getting it done quickly.
For organizations considering similar deployments, the key takeaway is clear: safe AI escalation is not a single feature but a layered system of checks and balances, each addressing different aspects of risk while working together to ensure that when AI cannot help safely, humans are ready to step in. Moreover, this cannot be built in isolation—it requires active collaboration between technical teams, domain experts, and the people who will actually use the system daily.
Conclusion
The work being done at Signpost illustrates that the future of AI in high-stakes domains lies not in replacement of human expertise, but in thoughtful collaboration between AI systems and human professionals. By treating escalation as a core feature rather than an afterthought, and by committing to systematic testing of multiple approaches, Signpost is charting a path toward AI deployment that is both ambitious in scale and responsible in implementation.